
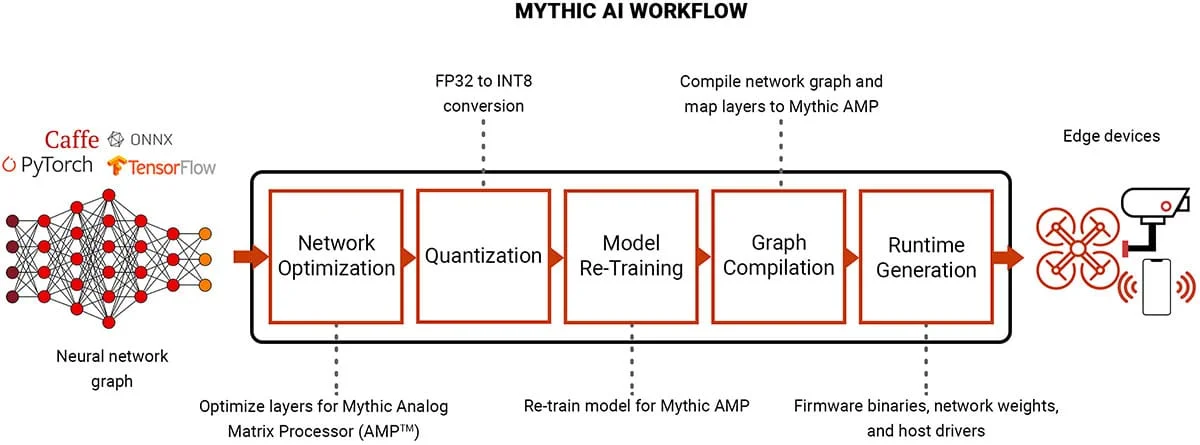
Fig. 1: AI Model Optimization Workflow. Curtesy: Mythic.ai
In the fast-paced world of artificial intelligence, optimization is the engine that powers performance, precision, and growth. From training neural networks to deploying real-time models on mobile devices, optimization ensures AI systems operate efficiently, learn faster, and scale with demand.
Fig. 2: AI Generated image. A modern UI showing machine learning hyperparameter
tuning using sliders,
learning curves, and performance graphs on a dark-themed dashboard.
Optimization begins with fine-tuning key components such as hyperparameters, activation functions, and network architectures. This process—essential in both traditional machine learning and deep learning—helps models generalize well while avoiding overfitting. Tools like grid search, Bayesian optimization, and random search are often employed to systematically discover the best configuration.
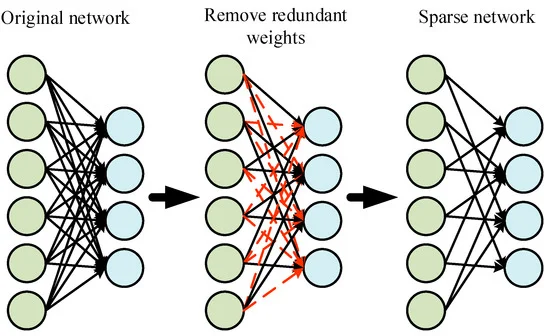
Fig. 3: Neural network diagram with pruned (cut-off) nodes and quantized weights.
Neural network pruning removes redundant weights, transforming a dense network into a sparse one—significantly improving efficiency without sacrificing accuracy.
For performance gains, engineers use techniques like model pruning, quantization, and knowledge distillation. These methods reduce model complexity and file size while maintaining accuracy—critical for AI running on edge devices, IoT sensors, or smartphones where computational resources are limited.

Fig. 4: AI Generated image. A cloud computing data center with glowing
lines representing
distributed AI processing across multiple nodes.
Scalability is a cornerstone of optimization. As AI workloads increase, systems must support more users, more data, and more predictions without slowing down. Leveraging distributed training, GPU clusters, and cloud-native frameworks ensures models scale horizontally without performance trade-offs.

Fig. 5: A comparison chart showing loss reduction with
different optimizers
(Adam, RMSprop, SGD) during AI model training.
Fig. 6: AI Generated image. A comparison chart showing loss reduction with
different optimizers
(Adam, RMSprop, SGD) during AI model training.
During training, optimizers like Adam, RMSprop, and SGD with momentum accelerate convergence, helping models learn faster with fewer epochs. Combined with learning rate schedulers and batch normalization, these strategies reduce training time and improve generalization on unseen data.

Fig. 7: AI Generated image. A sleek analytics dashboard displaying real-time
AI performance
metrics, alerts for retraining, and model accuracy over time.
Optimization doesn’t stop after deployment. Continuous monitoring, model retraining, and
performance evaluation are necessary to maintain relevance in dynamic environments. Automated
pipelines help retrain models with new data, ensuring they adapt to concept drift and evolving
customer needs.
Optimization is more than a technical step—it's a strategic imperative that turns experimental AI
into scalable, robust, and intelligent solutions. By investing in optimization across every layer
of the AI pipeline, organizations unlock real value and long-term success in the age of
intelligent systems.
© 2025 HoqueAI. All rights reserved. | Privacy Policy