
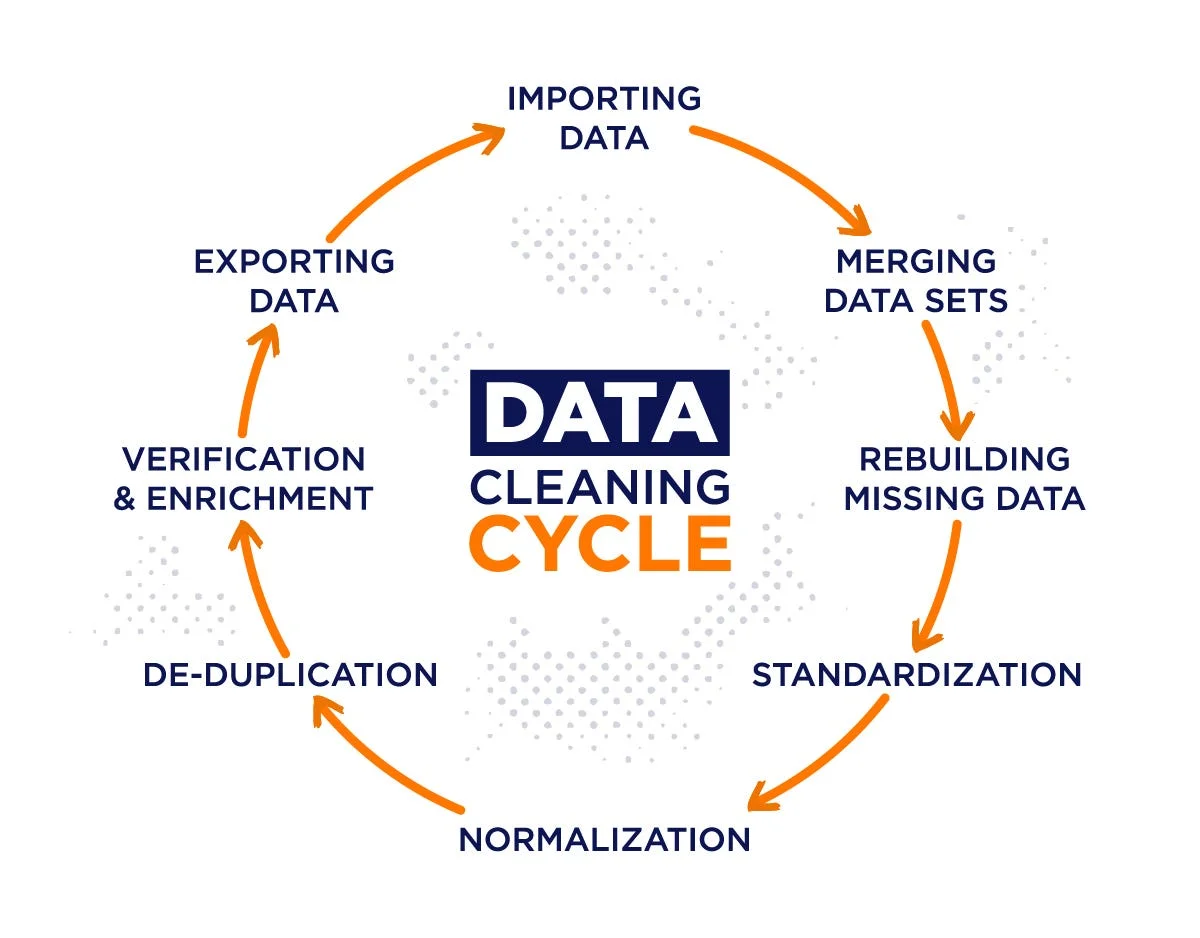
Fig. 1: Data Cleaning and Processing Pipeline.
Data analysis and processing form the critical foundation for building robust and accurate AI
systems. Before any model training begins, the quality and structure of data must be ensured.
Effective data workflows are essential to unlocking patterns, reducing biases, and
driving intelligent outcomes.
The process often begins with raw, unstructured, and inconsistent data sourced from diverse
formats such as text files, image collections, spreadsheets, or databases. To ensure reliability,
data cleaning techniques are applied—addressing missing values, correcting format inconsistencies,
removing outliers, and eliminating noise.

Fig. 2: AI Generated image: Data Cleaning concept. A split image showing
unclean,
inconsistent spreadsheet data on the left and clean, structured data on the right.
Exploratory Data Analysis (EDA) plays a pivotal role in uncovering trends, correlations, and anomalies. With the help of visual tools like Seaborn and Matplotlib, data scientists identify key attributes and visualize relationships, shaping the direction of model development. Statistical analysis and dimensionality reduction methods like Principal Component Analysis (PCA) streamline large feature spaces, making them more manageable and informative.
Fig. 3: AI Generated image: Exploratory data analysis. An AI engineer viewing
data
dashboards with colorful bar charts, histograms, and correlation matrices.

Fig. 4: AI Generated image: Conceptual illustration showing raw data turning
into advanced features
through transformation paths. Data pipelines visualized with digital lines
and code overlays.
Automation and reproducibility are maintained through scripting and workflow management using
Python libraries such as Pandas, NumPy, and Scikit-learn. These tools help create scalable
pipelines capable of handling large datasets in real time.
In time-series and sequential data projects, advanced techniques such as smoothing, lag generation,
and rolling windows are used to retain context and improve performance. For computer vision tasks,
image preprocessing, augmentation, and pixel normalization ensure quality and consistency.

Fig. 5: AI Generated image: Dimensionality Reduction using PCA. Abstract data
cloud with many scattered points
being compressed into 2D or 3D clusters using PCA. Futuristic tech
design with clear visual mapping.
A strong feedback loop is maintained between model outputs and data improvements. Insights from model
errors help refine datasets, retrain models with improved inputs, and drive incremental performance
gains.
Ultimately, the strength of any AI solution lies in the integrity of its data pipeline. With strategic
analysis and efficient processing, the foundation is laid for high-performance, real-world AI systems.
Fig. 6: AI Generated image: Automated Data Pipeline. Illustration of an
AI-powered automated data pipeline showing flow from raw
data ingestion to preprocessing, feature
engineering, and model deployment. Gears and icons representing each stage
Automated data pipelines are essential for efficiently managing the flow of data from multiple sources to storage, processing, and analytics systems. By automating tasks such as data ingestion, transformation, and loading (ETL/ELT), these pipelines eliminate the need for manual handling, significantly reducing errors and saving time. They ensure data is cleaned, validated, and enriched consistently, providing high-quality inputs for analysis and machine learning models. Technologies like Apache Airflow, AWS Glue, and Google Cloud Dataflow enable orchestration of these workflows at scale. Automated pipelines also support real-time data processing and integrate seamlessly with cloud platforms for flexibility and scalability. Their built-in monitoring and logging capabilities help maintain reliability and detect issues early. In modern AI systems, they play a foundational role by delivering timely, accurate, and structured data that powers intelligent decision-making.
© 2025 HoqueAI. All rights reserved. | Privacy Policy