

AI Generated image: K-Means Clustering, PCA and Image Compression
This project demonstrates the application of unsupervised learning techniques such as K-Means Clustering and Principal Component Analysis (PCA) for effective data visualization, image compression, and dimensionality reduction.
Understanding K-Means Algorithm & Principal Component Analysis (PCA)

Image 1: K-Means Algorithm & Principal Component Analysis (PCA)
In this project, we explore two fundamental machine learning techniques: K-Means Clustering and Principal Component Analysis (PCA). These techniques are widely used in data compression, pattern recognition, and computer vision. Through practical examples, we demonstrate how clustering helps reduce complexity in images and how dimensionality reduction preserves essential features while simplifying data representation.
K-Means Clustering is an unsupervised learning algorithm used to group similar data points into K clusters. K-means clustering is the Process in clustering similar data points in a 2D space into groups and widely used in grouping like:
In the context of image processing, we apply K-Means to perform color quantization, reducing the number of colors in an image while maintaining visual integrity.
The goal of K-Means is to minimize the total within-cluster variance, also known as the cost function (J):
\[ J = \sum_{i=1}^{m} \sum_{k=1}^{K} w_{ik} || x_i - C_k ||^2 \]
where:
Centroid is the center of a cluster. It is an imaginary point that represents the average position of all points in that cluster.
The centroid of a cluster \( k \) is calculated as the mean of all points \( x_i \) in that cluster:
\[ C_k = \frac{1}{N_k} \sum_{i=1}^{N_k} x_i \]
where:
Principal Component Analysis (PCA) is a powerful dimensionality reduction technique that finds the most important features in high-dimensional data. PCA is particularly useful in face recognition, where we extract key facial features to represent images efficiently.
Through these examples, we highlight the power of unsupervised learning techniques in image processing and data compression. Let’s dive in! 🚀
Python:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import scipy.io # Used to load the OCTAVE *.mat files
from random import sample # Used for random initialization
import scipy.misc # Used to show matrix as an image
import matplotlib.cm as cm # Used to display images in a specific colormap
from scipy import linalg # Used for the "SVD" function
Exppanation:
%matplotlib inline command ensures that plots appear directly in Jupyter Notebook.numpy is used for numerical operations, especially handling matrices and arrays.matplotlib.pyplot is used for visualization.scipy.io is used to read .mat files (MATLAB format).random.sample helps in randomly selecting data points for initialization.scipy.misc and matplotlib.cm are used for image processing and visualization.scipy.linalg provides linear algebra functions, including Singular Value
Decomposition (SVD), which is useful for Principal Component Analysis (PCA)..mat File
Python:
datafile = r'd:\mlprojects\data\ex7data2.mat'
mat = scipy.io.loadmat(datafile)
X = mat['X'] # X shaped (300,2)
Here:
ex7data2.mat is loaded using scipy.io.loadmat().X = mat['X'] extracts the feature matrix X from the .mat file.X.shape = (300,2) means that we have 300 data points, each with two coordinates (x1, x2).
Python:
K = 3 # Set Number of centroids... K = 3
initial_centroids = np.array([[3,3],[6,2],[8,5]])
Here:
Python codes:
# Function to visualize data points and centroids
def plotData(myX, mycentroids, myidxs=None):
"""
Function to plot the data and color it accordingly.
myidxs should be the latest iteration index vector
mycentroids should be a vector of centroids, one per iteration
"""
colors = ['b', 'g', 'gold', 'darkorange', 'salmon', 'olivedrab']
assert myX[0].shape == mycentroids[0][0].shape
assert mycentroids[-1].shape[0] < = len(colors)
# If idxs is supplied, divide up X into colors
if myidxs is not None:
assert myidxs.shape[0] == myX.shape[0]
subX = []
for x in range(mycentroids[0].shape[0]):
subX.append(np.array([myX[i] for i in range(myX.shape[0]) if myidxs[i] == x]))
else:
subX = [myX]
fig = plt.figure(figsize=(7,5))
for x in range(len(subX)):
newX = subX[x]
plt.plot(newX[:,0], newX[:,1], 'o', color=colors[x],
alpha=0.75, label='Data Points: Cluster %d' % x)
plt.xlabel('x1', fontsize=14)
plt.ylabel('x2', fontsize=14)
plt.title('Plot of X Points', fontsize=16)
plt.grid(True)
# Drawing a history of centroid movement
tempx, tempy = [], []
for mycentroid in mycentroids:
tempx.append(mycentroid[:,0])
tempy.append(mycentroid[:,1])
for x in range(len(tempx[0])):
plt.plot(tempx, tempy, 'rx--', markersize=8)
plt.legend()
plt.show()
def plotData(myX, mycentroids, myidxs=None) visualizes the data points and centroids.myidxs (cluster assignments) is provided, it groups data points by cluster.
Python:
#Plot the initial data and centroid:
plotData(X, [initial_centroids])
Output:
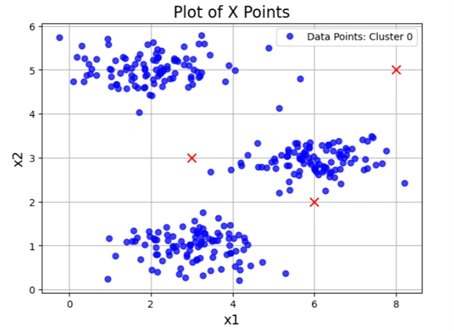
Image 2: Initial data visualization
Python:
def distSquared(point1, point2):
assert point1.shape == point2.shape
return np.sum(np.square(point2 - point1))
def distSquared(point1, point2) computes the squared Euclidean distance between two points.Python codes:
Python:
def findClosestCentroids(myX, mycentroids):
idxs = np.zeros((myX.shape[0], 1))
for x in range(idxs.shape[0]):
mypoint = myX[x]
mindist, idx = 9999999, 0 # Initialize with a large number
for i in range(mycentroids.shape[0]):
mycentroid = mycentroids[i]
distsquared = distSquared(mycentroid, mypoint)
if distsquared ≪ mindist:
mindist = distsquared
idx = i
idxs[x] = idx # Assign closest centroid index
return idxs
def findClosestCentroids(myX, mycentroids) assigns each data point in X to the nearest centroid.
Python:
idxs = findClosestCentroids(X, initial_centroids)
print(idxs[:3].flatten()) # Print the first 3 cluster assignments
Output:
[0. 2. 1.]
findClosestCentroids is called with X (data points) and initial_centroids (three predefined centroids).
Python:
plotData(X, [initial_centroids], idxs)
Output:
Clustered data graph
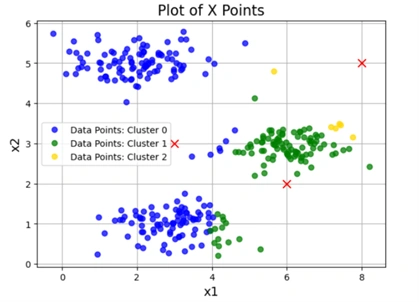
Image 3: Clustered graph
Python:
def computeCentroids(myX, myidxs):
"""
Function takes in the X matrix and the index vector
and computes a new centroid matrix.
"""
subX = []
for x in range(len(np.unique(myidxs))):
subX.append(np.array([myX[i] for i in range(myX.shape[0]) if myidxs[i] == x]))
return np.array([np.mean(thisX,axis=0) for thisX in subX])
def computeCentroids(myX, myidxs) computes the new centroid positions after assigning data points to clusters.myX: The dataset (each row is a data point).myidxs: The cluster assignments for each point (from findClosestCentroids).Python codes:
Python:
def runKMeans(myX, initial_centroids, K, n_iter):
"""
Function that actually does the iterations
"""
centroid_history = []
current_centroids = initial_centroids
for myiter in range(n_iter):
centroid_history.append(current_centroids)
idxs = findClosestCentroids(myX, current_centroids)
current_centroids = computeCentroids(myX, idxs)
return idxs, centroid_history
def runKMeans(myX, initial_centroids, K, n_iter) implements the iterative K-means clustering process.myX: The dataset.initial_centroids: Initial centroid positions.K: Number of clusters.n_iter: Number of iterations for K-means.centroid_history.findClosestCentroids).computeCentroids).centroid_history allows visualization of centroid movement.
Python:
idxs, centroid_history = runKMeans(X, initial_centroids, K=3, n_iter=10)
Runs the runKMeans function with:
X: The dataset.initial_centroids: The starting centroids.K=3: Three clusters.n_iter=10: The algorithm iterates ten times.What Happens Here?
idxs.centroid_history.
Python:
plotData(X, centroid_history, idxs)
Output:
Clustered image
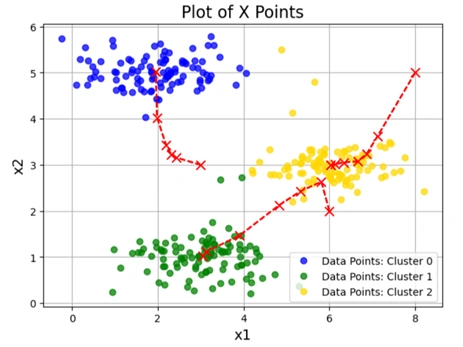
Image 4: K-means Clustering process over multiple iterations
This is a visualization of the K-means clustering process over multiple iterations.
The plot shows:
Python:
def chooseKRandomCentroids(myX, K):
rand_indices = sample(range(0,myX.shape[0]),K)
return np.array([myX[i] for i in rand_indices])
Explanation
def chooseKRandomCentroids(myX, K) selects K random points from
the dataset X to use as initial centroids for K-Means clustering.sample(range(0,myX.shape[0]),K) randomly selects K unique indices from the dataset.🛠 Why is this needed?
Python:
for x in range(3): #Let's choose random initial centroids
idxs, centroid_history = runKMeans(X,chooseKRandomCentroids(X,K=3),
K=3,n_iter=10)
plotData(X,centroid_history,idxs)
Output:
3 different clustering graphs
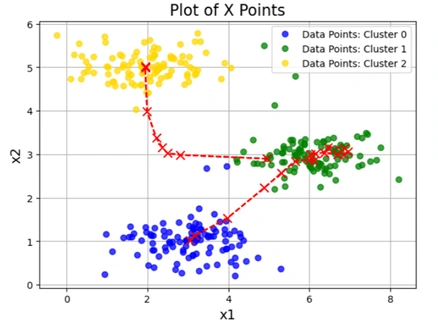
Image 5: K-means Clustering graph 1 with different initial Centroids
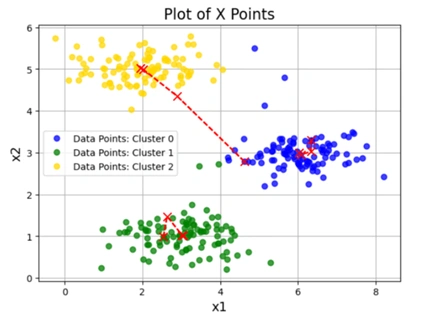
Image 6: K-means Clustering graph 2 with different initial Centroids
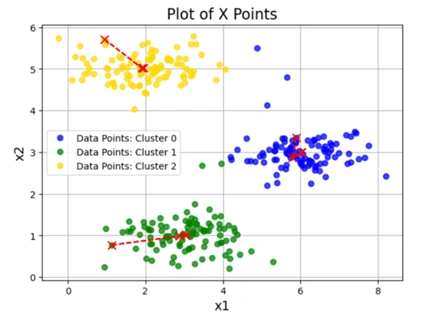
Image 7: K-means Clustering graph 3 with different initial Centroids
Loop runs 3 times:
chooseKRandomCentroids(X, K=3).runKMeans(X, initial_centroids, K=3, n_iter=10).plotData(X, centroid_history, idxs) generates a visualization of the clustering process.1️⃣ Effect of Random Initialization:
2️⃣ Centroid Movement Over Iterations:
3️⃣ Final Cluster Assignments:
An alpha channel is an additional layer in an image that controls transparency. It is mainly used in RGBA images, where:
A fully opaque pixel has an alpha value of 255, while a fully transparent pixel has an alpha value of 0.
Image 8: K-means Clustering graph 3 with different initial Centroids
When performing K-Means clustering for image compression, removing the alpha channel is necessary due to the following reasons:
- The clustering algorithm groups colors (R, G, B), not transparency levels.
- If the alpha channel is included, K-Means would treat transparent and opaque pixels as different colors, leading to inaccurate clustering.
- Many image processing functions expect a 3-channel (RGB) image and do not support 4-channel (RGBA) images.
- Including the alpha channel may cause errors or unexpected results.
- Removing the alpha channel ensures that all pixels have the same structure (R, G, B values only).
- This simplifies reshaping and processing the image for compression.
In our code, we check if the image has an alpha channel and remove it:
# Check if the image has an alpha channel (RGBA format)
if A.shape[2] == 4:
A = A[:, :, :3] # Keep only the first three channels (RGB)
✅ This keeps only the first 3 channels (R, G, B) and discards transparency.
While removing the alpha channel is essential for K-Means clustering, it is useful in other cases like:
For image compression, removing the alpha channel helps produce a clean and accurate color clustering.
This part of the project applies K-Means clustering to an image to perform image compression by reducing the number of unique colors in the image.
Python codes:
import imageio.v2 as imageio
import matplotlib.pyplot as plt
import numpy as np
# Load image
datafile = r'd:\mlprojects\data\bird_small2.png'
A = imageio.imread(datafile)
# Check if image has 4 channels (RGBA), convert to RGB
if A.shape[2] == 4: # Check if there's an alpha channel
A = A[:, :, :3] # Keep only the first three channels (RGB)
# Display shape and image
print("A shape after removing alpha channel:", A.shape)
plt.imshow(A)
plt.axis("off") # Hide axes
plt.show()
A = A / 255.0 # Normalize pixel values (0 to 1)
A = A.reshape(-1, 3) # Reshape image to (num_pixels, 3)
print("New A shape:", A.shape)
# Run k-means clustering
myK = 16
idxs, centroid_history = runKMeans(A, chooseKRandomCentroids(A, myK), myK, n_iter=10)
Comments:
In the codes by myK = 16, we explicitly set 16 centroids enabling to
store 16 colors in the future.
Output:

Image 9: Bird image for compression after removing alpha channel
The output indicates that now the image is of (565, 310, 3), which means image is:
At the bottom of output image "New A shape: (175150, 3)" indicates that:
Python:
idxs = findClosestCentroids(A, centroid_history[-1])
What this does:
centroid_history[-1] contains the final centroid positions after 10 iterations of K-Means.idxs stores the index of the closest centroid for each pixel in the reshaped image.✅ At this point, each pixel is mapped to one of the 16 colors from K-Means clustering.
final_centroids = centroid_history[-1]
final_image = np.zeros((idxs.shape[0], 3)) # Create new image with only 16 colors
for x in range(final_image.shape[0]):
final_image[x] = final_centroids[int(idxs[x].item())] # ✅ Use .item() to extract scalar
What this does:
final_centroids = centroid_history[-1] → Stores the final 16 centroid colors.final_image = np.zeros((idxs.shape[0], 3)) → Creates an empty array for
the compressed image.final_image to the corresponding centroid
color.✅ At this point, the image is reconstructed using only 16 unique colors instead of the original full-color spectrum.
orig_height, orig_width = 565, 310 # Use the correct values # Get the original image dimensions
plt.figure() # Reshape the original and compressed images correctly
dummy = plt.imshow(A.reshape(orig_height, orig_width, 3)) # ✅ Correct shape
plt.figure()
dummy = plt.imshow(final_image.reshape(orig_height, orig_width, 3)) # ✅ Correct shape
plt.show()
What this does:
plt.figure() and plt.imshow(A.reshape(orig_height, orig_width, 3))plt.figure() and plt.imshow(final_image.reshape(orig_height, orig_width, 3))plt.show() → Renders both images.✅ At this point, two images are displayed as output:

Image 10: Bird image for compression after removing alpha channel
While compression significantly reduces the number of unique colors in the image, it does not degrade the overall quality. Instead, it enhances the separation of different regions, making boundaries between colors more visible.
Principal Component Analysis (PCA) is a dimensionality reduction technique used in machine learning and data analysis. It helps reduce the number of features while preserving as much variance in the data as possible. PCA works by transforming the original correlated features into a new set of uncorrelated features called Principal Components (PCs), ranked by their importance.
Python codes:
datafile = r'd:\mlprojects\data\ex7data1.mat' # Load dataset
mat = scipy.io.loadmat(datafile) # Read .mat file
X = mat['X'] # Extract feature matrix
# Quick plot of the dataset
plt.figure(figsize=(7,5))
plot = plt.scatter(X[:,0], X[:,1], s=30, facecolors='none', edgecolors='b')
plt.title("Example Dataset", fontsize=18)
plt.grid(True)
plt.show()
Output:

Image 11: Scattered graph before applying PCA
This code generates a scatter plot of the dataset. The points in the graph represent the original data points before applying PCA.
Python codes:
def featureNormalize(myX):
# Compute the mean of each feature
means = np.mean(myX, axis=0)
# Subtract the mean from the dataset
myX_norm = myX - means
# Compute the standard deviation and normalize
stds = np.std(myX_norm, axis=0)
myX_norm = myX_norm / stds
return means, stds, myX_norm
Python:
def getUSV(myX_norm):
cov_matrix = myX_norm.T.dot(myX_norm) / myX_norm.shape[0] #Compute the covariance matrix
# Perform Singular Value Decomposition (SVD)
U, S, V = scipy.linalg.svd(cov_matrix, full_matrices=True, compute_uv=True)
return U, S, V
🔹 What is happening here?
U: Principal component directions (eigenvectors).S: Strength (variance explained) of each component.V: Not directly used in PCA.
Python:
means, stds, X_norm = featureNormalize(X) # Normalize features
U, S, V = getUSV(X_norm) # Run SVD to compute principal components
🔹 Purpose of This Step
Python codes:
# Quick scatter plot of original data
plt.figure(figsize=(7,5))
plt.scatter(X[:,0], X[:,1], s=30, facecolors='none', edgecolors='b')
# Add principal component lines
plt.plot([means[0], means[0] + 1.5*S[0]*U[0,0]],
[means[1], means[1] + 1.5*S[0]*U[0,1]],
color='red', linewidth=3, label='First Principal Component')
plt.plot([means[0], means[0] + 1.5*S[1]*U[1,0]],
[means[1], means[1] + 1.5*S[1]*U[1,1]],
color='fuchsia', linewidth=3, label='Second Principal Component')
# Labels, grid, and legend
plt.title("Example Dataset: PCA Eigenvectors Shown", fontsize=18)
plt.xlabel('x1', fontsize=18)
plt.ylabel('x2', fontsize=18)
plt.grid(True)
plt.legend(loc=4) # Bottom-right legend
plt.show()
Output graph
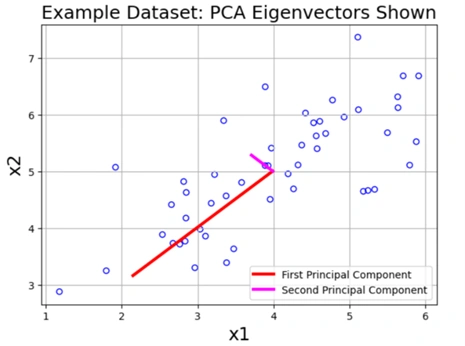
Image 12: Scattered graph after applying PCA
Output Explanation
This graph displays the original data points along with two principal component vectors.
🔹 Understanding the Principal Components
✅ Key Observations
Python:
def projectData(myX, myU, K):
Ureduced = myU[:, :K]
z = myX.dot(Ureduced)
return z
Explanation: Projects the dataset onto the top K principal components, reducing dimensionality.
Python:
z = projectData(X_norm, U, 1)
print('Projection of the first example is %0.3f.' % z[0].item())
Output:
Projection of the first example is 1.496.
Explanation: This value represents the new coordinate of the first data point after projection onto the first principal component.
Python:
def recoverData(myZ, myU, K):
Ureduced = myU[:, :K]
Xapprox = myZ.dot(Ureduced.T)
return Xapprox
Explanation: Reconstructs an approximation of the original dataset from the projected data.
Python:
X_rec = recoverData(z, U, 1)
print('Recovered approximation of the first example is ', X_rec[0])
Outpot:
Recovered approximation of the first example is [-1.05805279 -1.05805279]
Explanation:
Python codes:
plt.figure(figsize=(7,5))
plt.scatter(X_norm[:,0], X_norm[:,1], s=30, facecolors='none', edgecolors='b', label='Original Data Points')
plt.scatter(X_rec[:,0], X_rec[:,1], s=30, facecolors='none', edgecolors='r', label='PCA Reduced Data Points')
for x in range(X_norm.shape[0]):
plt.plot([X_norm[x,0], X_rec[x,0]], [X_norm[x,1], X_rec[x,1]], 'k--')
plt.title("Example Dataset: Reduced Dimension Points Shown", fontsize=14)
plt.xlabel('x1 [Feature Normalized]', fontsize=14)
plt.ylabel('x2 [Feature Normalized]', fontsize=14)
plt.grid(True)
plt.legend(loc=4)
plt.xlim((-2.5,2.5))
plt.ylim((-2.5,2.5))
plt.show()
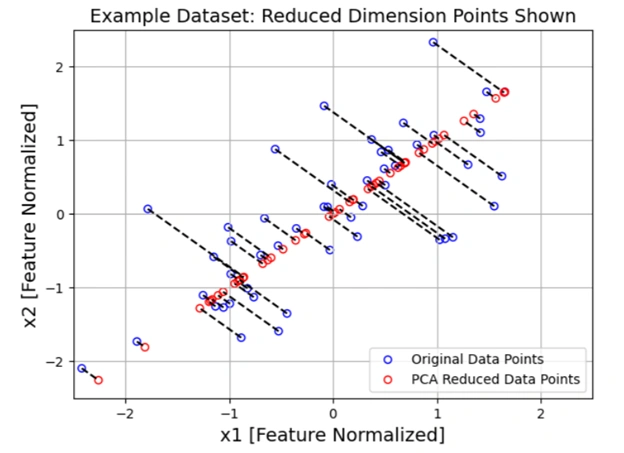
Image 13: Graph showing projected data onto a one-dimensional space
Python:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
from PIL import Image
import scipy.io
✅ Loaded the required libraries for numerical computation, visualization, and image processing.
Python:
datafile = r'd:\mlprojects\data\ex7faces.mat'
mat = scipy.io.loadmat(datafile)
X = mat['X']
✅ This code loads the face dataset from a .mat file. The dataset X contains grayscale ima ges of faces, where each row represents a 32×32 pixel image as a flattened vector of 1024 values.
Python:
def getDatumImg(row):
""" Convert a row vector into a 32x32 image """
width, height = 32, 32
square = row.reshape(width, height)
return square.T
✅ This function reshapes one row (flattened 1024 pixels) back into a 32×32 grayscale image.
Python codes:
def displayData(myX, mynrows=10, myncols=10):
""" Display 100 face images in a 10x10 grid """
width, height = 32, 32
nrows, ncols = mynrows, myncols
big_picture = np.zeros((height * nrows, width * ncols))
irow, icol = 0, 0
for idx in range(nrows * ncols):
if icol == ncols:
irow += 1
icol = 0
iimg = getDatumImg(myX[idx])
big_picture[
irow * height : irow * height + iimg.shape[0],
icol * width : icol * width + iimg.shape[1]
] = iimg
icol += 1
# Normalize to 0-255 for better contrast
big_picture = (big_picture - np.min(big_picture)) / (np.max(big_picture) - np.min(big_picture)) * 255
big_picture = big_picture.astype(np.uint8)
# Display the image
fig, ax = plt.subplots(figsize=(10, 10))
img = Image.fromarray(big_picture)
ax.imshow(img, cmap=cm.Greys_r)
# Set axis labels
ax.set_xticks(np.linspace(0, width * ncols, num=5))
ax.set_xticklabels(np.linspace(0, width * ncols, num=5, dtype=int))
ax.set_yticks(np.linspace(0, height * nrows, num=5))
ax.set_yticklabels(np.linspace(height * nrows, 0, num=5, dtype=int))
plt.show()
✅ This function arranges 100 face images in a 10×10 grid and displays them.
Python:
displayData(X)
Output:
Face images

Image 14: 10 x 10 grid of faces
✅ Output Explanation
🔹 Significance of Output:
Next Steps: Apply PCA to reduce face image dimensions and reconstruct them with minimal loss.
Python:
# Feature normalize
means, stds, X_norm = featureNormalize(X)
# Run SVD
U, S, V = getUSV(X_norm)
What’s Happening Here?
Eigenvalues: An Intuitive Explanation
Eigenvalues are scalars that indicate how much a corresponding eigenvector is stretched or shrunk during a linear transformation.
For a given square matrix \( A \), an eigenvalue \( \lambda \) and an eigenvector \( v \) satisfy the equation:
\[ A v = \lambda v \]
where:
In Principal Component Analysis (PCA), eigenvalues tell us how much variance (information) is captured by each principal component:
When performing dimensionality reduction, we keep only the top k eigenvalues and their corresponding eigenvectors to retain the most important features.
Python:
# Visualize the top 36 eigenvectors found # "Eigenfaces" lol
displayData(U[:,:36].T, mynrows=6, myncols=6)
Output:
6 x 6 image with fade faces

Image 15: 6 x 6 fade face like objects
Eigenfaces are a set of eigenvectors used in Principal Component Analysis (PCA) for facial recognition. They represent the most important features (principal components) of a dataset containing face images.
Eigenfaces are an efficient way to store and recognize faces using PCA. By keeping only the most significant eigenfaces, we can compress face data while preserving its essential features.
Python:
# Project each image down to 36 dimensions
z = projectData(X_norm, U, K=36)
Python:
# Attempt to recover the original data
X_rec = recoverData(z, U, K=36)
Python:
# Plot the dimension-reduced data
displayData(X_rec)
Output:
10 x 10 Image

Image 16: 10 x 10 Reconstructed image fade face like objects
This demonstrates how Principal Component Analysis (PCA) reduces dimensionality while still retaining essential image features.
Python:
# Feature normalize
means, stds, A_norm = featureNormalize(A)
# Run SVD
U, S, V = getUSV(A_norm)
Python:
# Use PCA to go from 3->2 dimensions
z = projectData(A_norm, U, 2)
Python codes:
# Make the 2D plot
subX = []
for x in range(len(np.unique(idxs))):
subX.append(np.array([A[i] for i in range(A.shape[0]) if idxs[i] == x]))
fig = plt.figure(figsize=(8,8))
for x in range(len(subX)):
newX = subX[x]
plt.plot(newX[:,0],newX[:,1],'.',alpha=0.3)
plt.xlabel('z1',fontsize=14)
plt.ylabel('z2',fontsize=14)
plt.title('PCA Projection Plot',fontsize=16)
plt.grid(True)
plt.show()
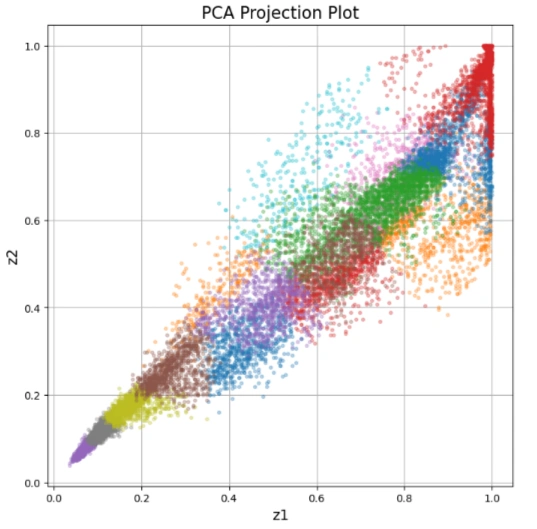
Image 17: Generated image
1. The PCA Projection Plot is a scatter plot where:
2. This visualization helps in understanding how colors are distributed in the image without needing a 3D RGB plot.
This is useful for image compression, color clustering, and feature extraction in computer vision tasks! 🚀
- PCA was applied to image data, starting with feature normalization and computing
Singular Value Decomposition (SVD) to extract principal components.
- This helped project high-dimensional image data into lower-dimensional spaces while
retaining important features.
- By extracting eigenfaces from a dataset of human faces, we visualized the most significant
facial features.
- Reducing image dimensions allowed us to compress and reconstruct faces while analyzing
how much detail was preserved.
- Images were projected onto a lower-dimensional subspace (e.g., 36 principal components) and
reconstructed to evaluate the loss of detail.
- The reconstructed images retained main features, demonstrating PCA’s effectiveness in
image compression.
- PCA was used to reduce RGB color data from 3D to 2D for easier visualization of color clusters.
- The final PCA projection plot illustrated how PCA can assist in image segmentation
and clustering.
This project successfully demonstrated PCA’s power in reducing data complexity while maintaining essential structure in images. From face recognition to color compression, PCA proves to be a valuable tool in machine learning and computer vision.
Future improvements could involve exploring non-linear dimensionality reduction techniques like t-SNE or Autoencoders for better visualization and reconstruction quality.
🚀 Thank you for following along!
I sincerely thank Prof. Andrew NG (DeepLearning.AI, Stanford University) for his inspiring courses that laid the foundation for this project.
 www.HoqueAi.com
www.HoqueAi.com