
AI Generated image: YOLOv12 for Forest Fire Detection
This project guides the preparation of high-quality datasets for YOLOv12, covering annotation, formatting, and splitting techniques using modern tools and standards.
Courtesy:https://github.com/argoverse/argoverse-api/issues/144.
Building a powerful object detection model with YOLOv12 starts with one critical step—preparing a high-quality dataset. A well-structured dataset is the backbone of an accurate and efficient model, helping it recognize a diverse range of objects in real-world scenarios.
In this guide, we’ll walk you through the best practices for dataset preparation, from annotating images with precision to organizing files in the ideal structure. You'll learn how to create a balanced dataset that includes a variety of people, animals, vehicles, objects, and scenes, ensuring your model generalizes well. Whether you’re working with common categories like those in COCO or custom objects like fire, number plates, or rare species, this guide will equip you with the knowledge to label every instance correctly and consistently.
We'll also cover essential tools, proper naming conventions, and how to split your dataset into training, validation, and test sets for optimal performance. By the end, you'll have a well-structured dataset ready to train a high-performing YOLOv12 model.
Let’s dive in and set the foundation for cutting-edge object detection! 🚀
Before training a YOLOv12 model, it’s crucial to ensure that the dataset meets specific quality and structural requirements. A well-prepared dataset improves model accuracy and generalization. Below are the key aspects to consider:

Use high-resolution images like the the image at the right Curtesy: todaysnorthumberland.ca
Avoid use of blurry image like one at the left.
To make a robust object detection model, include diverse samples:

Diverse samples in different lighting, angles, and backgrounds.
Each object in an image must be labeled with a unique numerical ID:
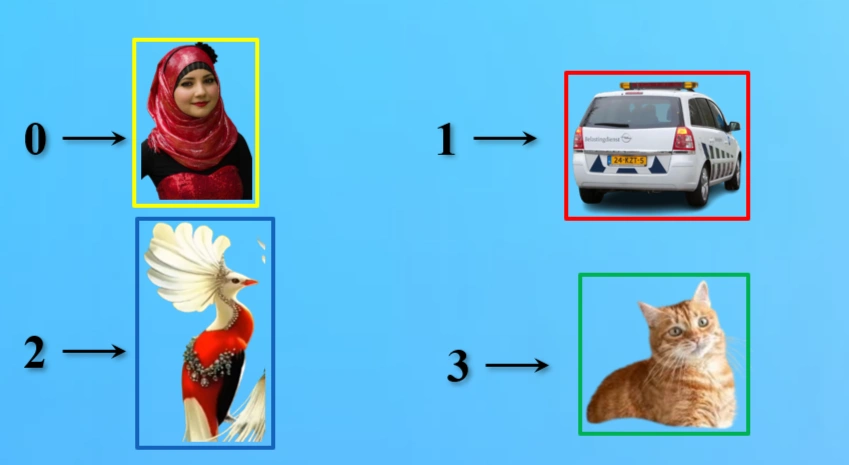
Unique ID for every objects.
Bounding box annotation format:
<class_id> <x_center> <y_center> <width> <height>
Annotation txt file has 5 columns for each class of objects. they are:
Image: dataset.png
Annotation: dataset.txt
Image dataset.png with bounding boxes
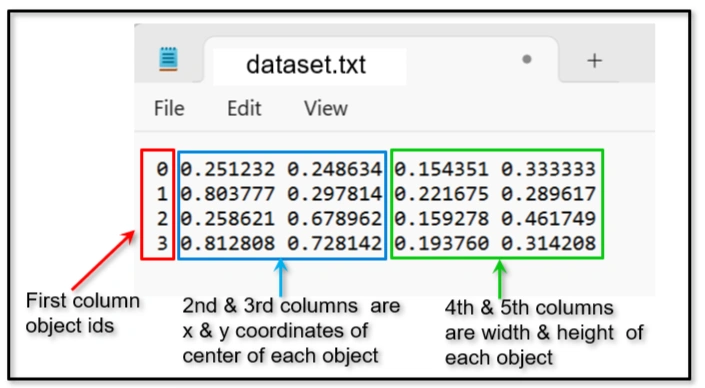
dataset.txt annotated file with same name as image
Unique ID for every objects.
The classes.txt file defines the object categories in the dataset. Each line represents a class name in order.
person
car
cat
dog
number_plate
The index of each class (starting from 0) corresponds to the class ID used in annotation files.

Best practice to make bounding box in one option only.
In this image, there are two approaches to labeling objects. A bounding box can either enclose only the visible portion of an object or encompass the entire object, including both visible and hidden parts. While both methods are valid, consistency is key. Mixing these approaches—labeling some objects partially while enclosing others fully—can lead to inconsistencies, ultimately affecting the accuracy and reliability of the dataset. To maintain uniformity, it is essential to choose one method and apply it consistently across all annotations.

Left Bad practice:No Bounding boxes on all instances of objects.
Right Best practice: Bounding boxes on all instances objects
For consistency and accuracy, it is essential to annotate all instances of every object in an image by creating bounding boxes around them. Incomplete annotations—where some objects are left without bounding boxes—can lead to inconsistencies and reduce the quality of the dataset. A thorough and systematic approach ensures reliable training data for optimal model performance.
When preparing a dataset for YOLOv12, one of the most important questions is: How many images are enough? The ideal dataset size depends on several factors, including the complexity of objects, the number of classes, and the variety within each class.
A well-balanced dataset should contain a diverse set of images, ensuring that all object categories are equally represented. If some classes have significantly fewer images than others, the model may struggle to detect them accurately. Aim for class balance to prevent bias in predictions.
For a high-performing object detection model:

AI-Generated image: Example of diverse images in a dataset containing a variety of objects in balanced proportions.
A well-structured dataset is the foundation of a strong YOLOv12 model. By focusing on quality, diversity, and balance, we set the stage for precise and reliable object detection.
Annotations play a crucial role in training a YOLOv12 model. They serve as ground truth metadata, providing essential information about object locations within images. A well-structured annotation ensures the model understands the object’s position, size, and class, leading to accurate detections.
YOLO (You Only Look Once) follows a simple text-based format. Each image has a corresponding annotation file with the same name but a .txt extension.
Each line in a YOLO annotation file represents an object in the image using the following structure:
<class_id> <x_center> <y_center> <width> <height>
Example Annotation:
0 0.512 0.478 0.324 0.280
1 0.703 0.615 0.210 0.320
By following these guidelines, we can create a high-quality dataset that enhances YOLOv12's accuracy and efficiency in real-world scenarios.
Creating high-quality annotations is crucial for training an accurate object detection model. Every object must be labeled with precision and consistency. Below is a step-by-step guide on annotating images using LabelImg and Roboflow.
Use either LabelImg or Roboflow for annotations. Install LabelImg using:
Command Prompt:
pip install labelImg
Launch it with:
Command Prompt:
labelImg
Open LabelImg, select your dataset folder, and set the annotation save directory.
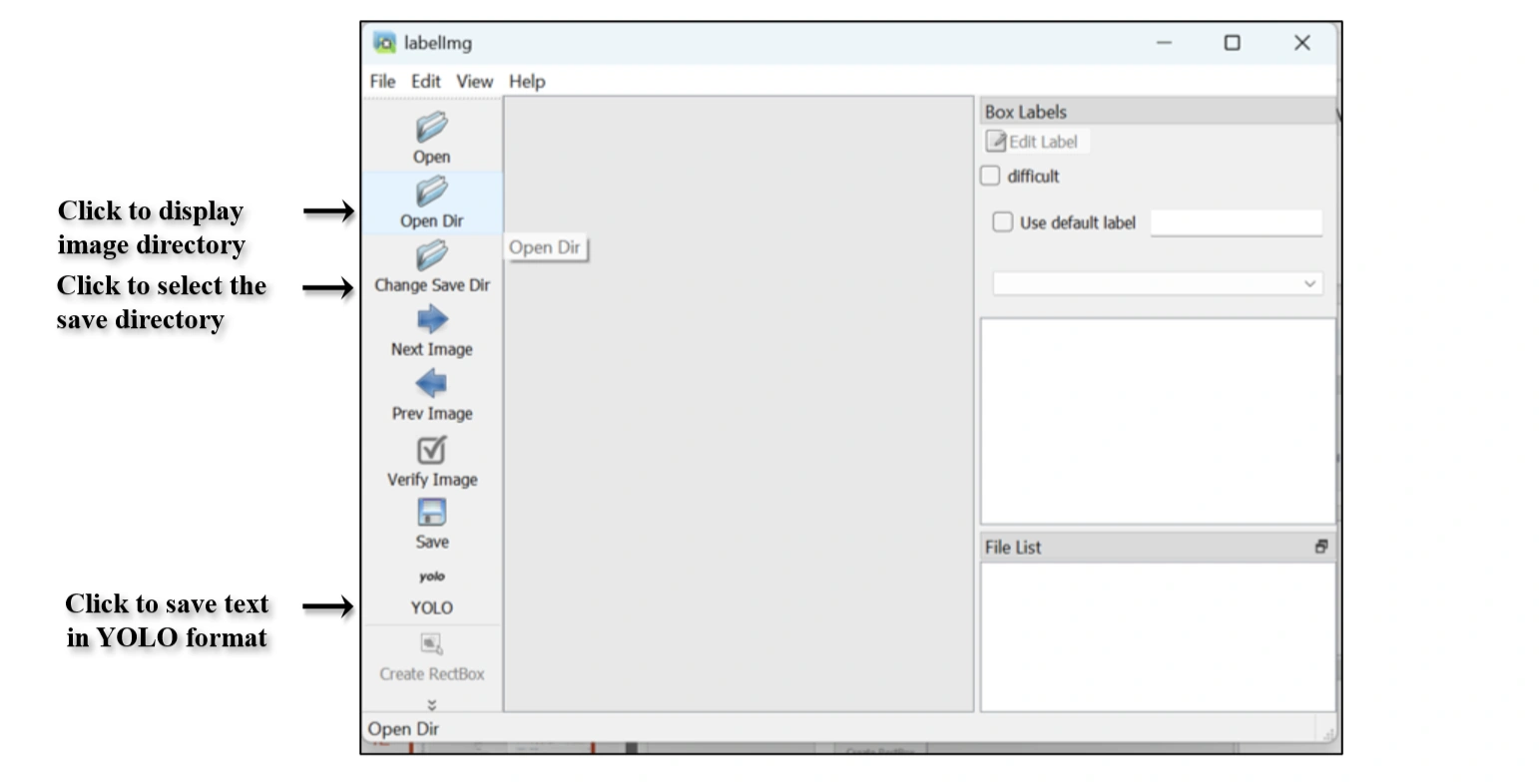
Click "Open Dr" option to load image folder in Labelimg.
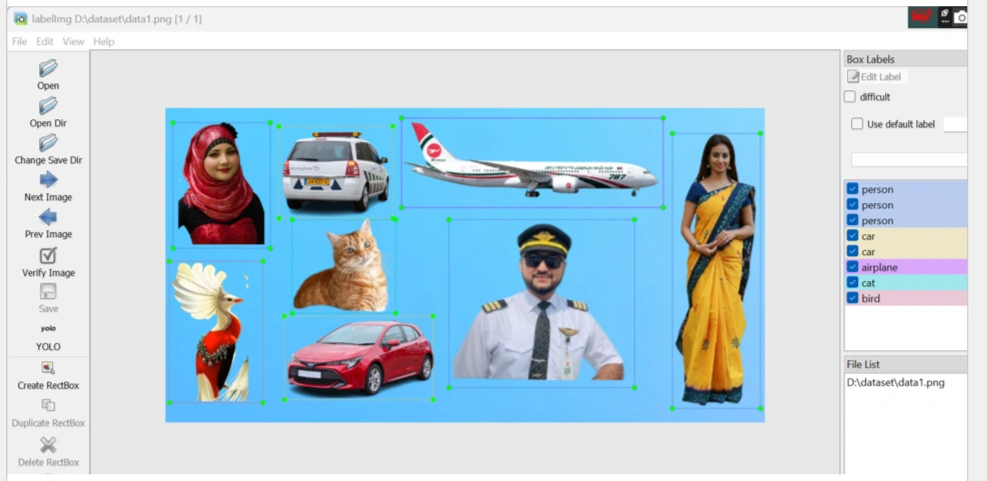
Loaded "Image folder " with menus in Labelimg.
Procedure to Create Bounding Boxes:
Each object must be assigned a class label. Ensure labels are consistent and precise.
Correct: number_plate, airplane, fire_extinguisher
Avoid: NP, Aircraft, exting
Annotations follow the YOLO format:
<class_id> <x_center> <y_center> <width> <height>
Example:
Following is our annotated txt file contents:
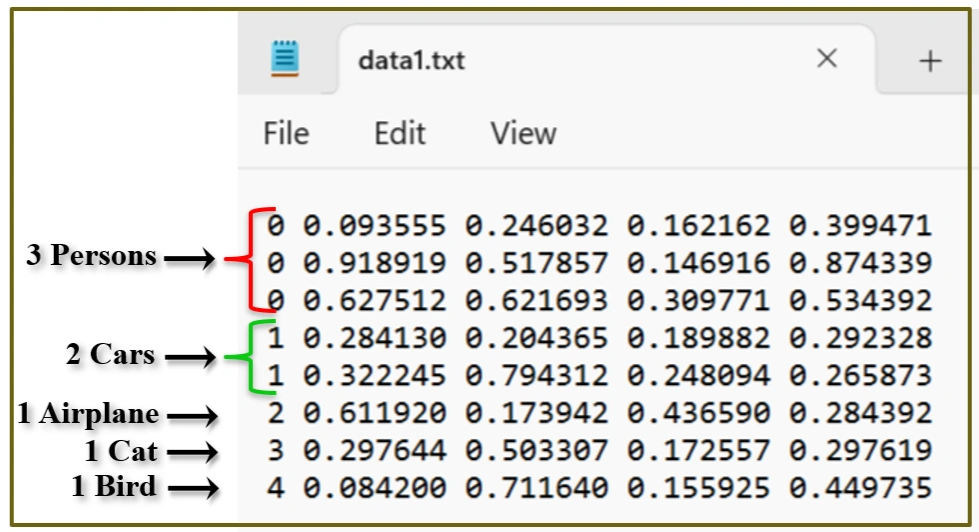
Loaded "data1.txt" file contents.
Ensure all objects are annotated correctly and consistently across images.

Left Bad practice:No Bounding boxes on all instances of objects.
Right Best practice: Bounding boxes on all instances objects
When preparing a dataset for YOLOv12, organizing files properly is crucial for training an efficient and accurate model. A well-structured dataset follows a systematic directory layout, ensuring seamless data access and consistency during training and evaluation.
Dataset/
│── images/
│ ├── train/ # Training images
│ ├── val/ # Validation images
│ ├── test/ # Test images
│── labels/
│ ├── train/ # Corresponding YOLO annotation text files for training images
│ ├── val/ # Corresponding YOLO annotation text files for validation images
│ ├── test/ # Corresponding YOLO annotation text files for test images
│── classes.txt # List of class names in the dataset
classes.txt file serves as a reference for object
categories, ensuring that annotations remain accurate and aligned with training expectations.
To train a YOLOv12 model effectively, we need to divide the dataset into three parts:
The commonly recommended dataset split is:
Small Dataset (1,000 Images)
Large Dataset (100,000 Images)
By following these best practices, you can create an effective dataset split that ensures accurate and generalizable results for YOLOv12. 🚀
Creating a high-quality dataset for YOLOv12 requires the right tools for image collection, annotation, and dataset management.
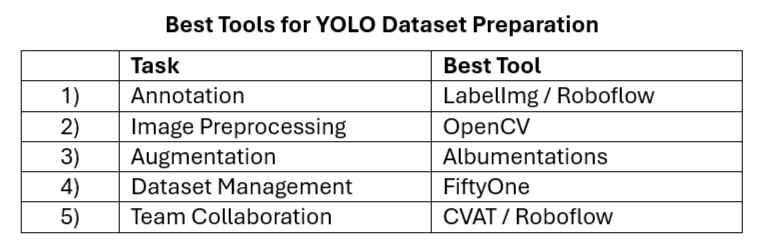
Best tools for data preparation
Choosing the right tool depends on the dataset size, annotation needs, and automation requirements. For simple YOLO dataset preparation, LabelImg is the best choice, but for larger datasets, Roboflow or CVAT might be more suitable. FiftyOne can be used for dataset management and debugging annotation errors.
Preparing a dataset for YOLOv12 is more than just collecting images and annotating objects—it is about ensuring precision, consistency, and diversity. A well-structured dataset lays the foundation for an accurate and efficient object detection model.
By carefully selecting high-quality images, maintaining class balance, and adhering to a structured annotation process, we can enhance the model’s learning capability. Splitting the dataset into training, validation, and test sets ensures robust evaluation, while following best practices in annotation and folder organization improves scalability and usability.
Utilizing the right tools, such as LabelImg, Roboflow, and CVAT, streamlines the annotation process and minimizes errors. Consistency in labeling, dherence to a proper naming convention, and maintaining annotation integrity across all images are crucial for achieving superior detection accuracy.
As technology advances, datasets will continue to evolve. However, the principles of structured dataset preparation, annotation accuracy, and strategic dataset splitting remain the cornerstones of training an efficient and reliable YOLOv12 model. By following these best practices, we can create datasets that drive powerful, real-world AI applications.